最近学校举办了一个模拟情侣72小时的活动,收到了大概500份个人数据,包括身高,年龄,自我介绍,理想的TA等数据。决定分析这些数据看看能不能得出一些因缺思厅的结论。
分析数据
数据全部在一张excel表中,那么首先我们就要将数据读取出来。这里我们使用pandas。了解过python数据分析或者machine learning的朋友应该都知道这个库,详细内容请看文档.
安装pandas
pip install pandas读取Excel
import pandas as pd
data = pd.read_excel("yue.xls")现在我们看看有哪些数据,如下我们运行data.dtypes可以看到所有的数据列和类型。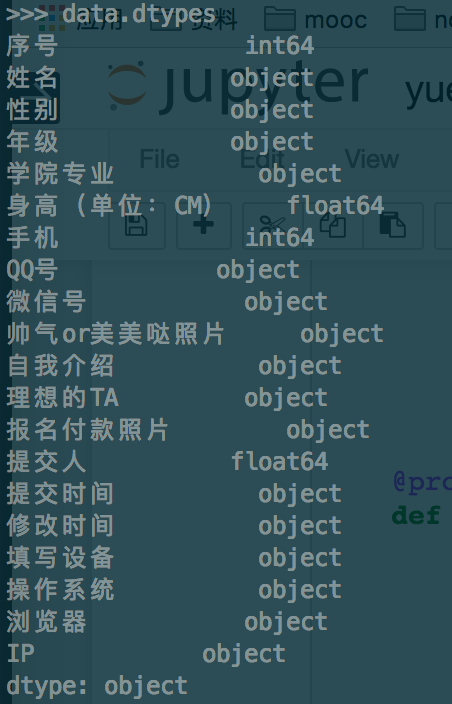
这次我们只需要性别和理想的TA,通过这两个数据分别得出男女生对伴侣的要求。
代码如下:
boy = data[data[u"性别"] == u"男"]
girl = data[data[u"性别"] == u"女"]
#将女生理想TA数据存入boy.txt
output = codecs.open('girl.txt', 'w','utf-8')
for want in girl[u'理想的TA']:
want = want.replace(u'模拟情侣','')
want = want.replace(u'交友','')
output.write(want +'\n')
output.close()
#将男生理想TA数据存入boy.txt
output1 = codecs.open('boy.txt', 'w','utf-8')
for want in boy[u'理想的TA']:
output1.write(want +'\n')
output1.close()有一点注意的由于用的是python2.7(推荐使用python3),编码问题还是很头痛的。这里引入了codece库处理编码问题,而不是直接打开txt文件。
生成结果
数据拿到了,现在我们将文本生成词云。这里我们用到一些库。jieba用来做中文分词,wordcloud用来生成词云。
cycler==0.10.0
jieba==0.38
matplotlib==1.5.3
numpy==1.11.2
pyparsing==2.1.10
python-dateutil==2.5.3
pytz==2016.7
six==1.10.0
wordcloud==1.2.1由于wordcloud库本身并不直接支持中文,我们需要自己加入一些参数。
# coding: utf-8
from os import path
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
import jieba
class WordCloud_CN:
'''
use package wordcloud and jieba
generating wordcloud for chinese character
'''
def __init__(self, stopwords_file):
self.stopwords_file = stopwords_file
self.text_file = text_file
@property
def get_stopwords(self):
self.stopwords = {}
f = open(self.stopwords_file, 'r')
line = f.readline().rstrip()
while line:
self.stopwords.setdefault(line, 0)
self.stopwords[line.decode('utf-8')] = 1
line = f.readline().rstrip()
f.close()
return self.stopwords
@property
def seg_text(self):
with open(self.text_file) as f:
text = f.readlines()
text = r' '.join(text)
seg_generator = jieba.cut(text)
self.seg_list = [
i for i in seg_generator if i not in self.get_stopwords]
self.seg_list = [i for i in self.seg_list if i != u' ']
self.seg_list = r' '.join(self.seg_list)
return self.seg_list
def show(self):
# wordcloud = WordCloud(max_font_size=40, relative_scaling=.5)
wordcloud = WordCloud(font_path=u'./static/simheittf/simhei.ttf',background_color="black", margin=5, width=1800, height=800)
wordcloud = wordcloud.generate(self.seg_text)
plt.figure()
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
if __name__ == '__main__':
stopwords_file = u'./static/stopwords.txt'
text_file = u'boy.txt'
generater = WordCloud_CN(stopwords_file)
generater.show()
女生的理想TA
男生的理想TA
由于数据量太小,暂时还没想到有什么更有趣的分析办法。打算写个爬虫去爬交友或者社交类网站,再做进一步数据分析。



