BERT阅读与总结
最近google放出的BERT引起了NLP领域很大的反响,在11项NLP tasks中取得了state-of-the-art的结果,包括NER、问答等领域的任务。看完论文和网上的讨论,总结了几个关键点。
BERT模型结构
BERT采用了Transformer Encoder的模型来作为语言模型,Transformer模型来自于论文《Attention is all you need》, 完全抛弃了RNN/CNN等结构,而完全采用Attention机制来进行input-output之间关系的计算,如下图中左半边部分所示,其中模型包括两个sublayer:
- Multi-Head Attention 来做模型对输入的Self-Attention
- Feed Forward 部分来对attention计算后的输入进行变换
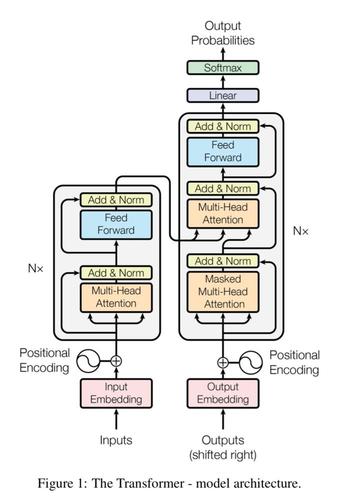
在模型结构上BERT与transformer并无太多区别,BERT采用了Transformer Encoder,也就是每个时刻的Attention计算都能够得到全部时刻的输入。
论文中将论文将层数(即Transformer blocks)表示为L,将隐藏大小表示为H,将self-attention heads的数量表示为A。在所有情况下,将feed-forward/filter 的大小设置为 4H,即H = 768时为3072,H = 1024时为4096。文章提出了两种不同大小的模型。
- BERT BASE: L=12,H=768,A=12,Total Parameters=110M
- BERT LARGE: L=24,H=1024,A=16,Total Parameters=340M
其中BERT LARGE ,它与OpenAI GPT具有相同的模型大小。不同的是,BERT Transformer使用双向self-attention,而GPT Transformer使用受限制的self-attention,其中每个token只能处理其左侧的上下文。在文献中,双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,因为它可以用于文本生成。如图所示为BERT与OpenAI GPT,ELMo的区别。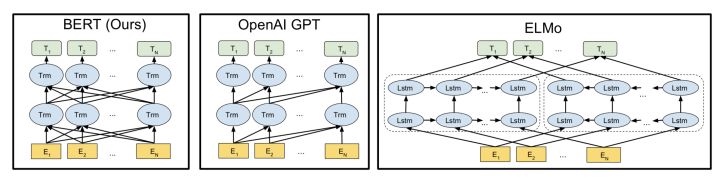
输入表示
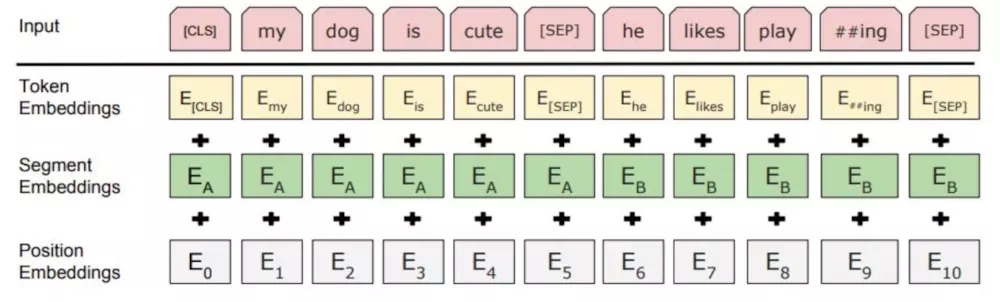
图中[CLS]表示该特征用于分类模型,对非分类模型,该符合可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
BERT的输入编码向量是token, segment and position embeddings的单位和.
- token即WordPiece嵌入:WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。示例中‘playing’被拆分成了‘play’和‘ing’。文中使用了30000个token的词汇表,使用##表示分词;
- 位置嵌入(Position Embedding):位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。
- 分割嵌入(Segment Embedding):用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。
预训练任务
论文提出了两个预训练任务,启到了非常关键的作用。
Masked Language Model(MLM)
Input:
the man [MASK1] to [MASK2] store
Label:
[MASK1] = went; [MASK2] = a把遮挡后的输入句子喂给一个深度Transformer用于编码(encoder),然后利用被遮挡位置对应的隐藏层状态(hidden state)去预测对应的词。
在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词。
- 80%直接替换为[Mask]:
my dog is hairy -> my dog is [mask] - 10%替换为其它任意单词:
my dog is hairy -> my dog is apple - 10%保留原始Token:
my dog is hairy -> my dog is hairy
加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’hairy‘。Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。并且随机替换只发生在所有token的1.5%(15%*10%),负面影响很小可以忽略不计。
MLM的缺点是每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。实验证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。
Next Sentence Prediction(NSP)
因为语言模型并不能理解两个句子之间的关系,然而句子关系对于一些NLP任务来说相当重要。因此,为了预训练一个句子关系模型,利用了一个非常简单的二分类任务。这个任务将两个句子顺次拼接起来,然后预测后一个句子是否是前一个句子的下一个句子。
Input:
the man went to a store [SEP] he bought a gallon of milk
Label:
IsNext
Input:
the man went to a store [SEP] penguins are flightless birds
Lable:
NotNext当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。如果是的话输出’IsNext‘,否则输出’NotNext‘。NotNext语句完全随机选出,最终的预训练模型在此任务上实现了97%-98%的准确率。
微调
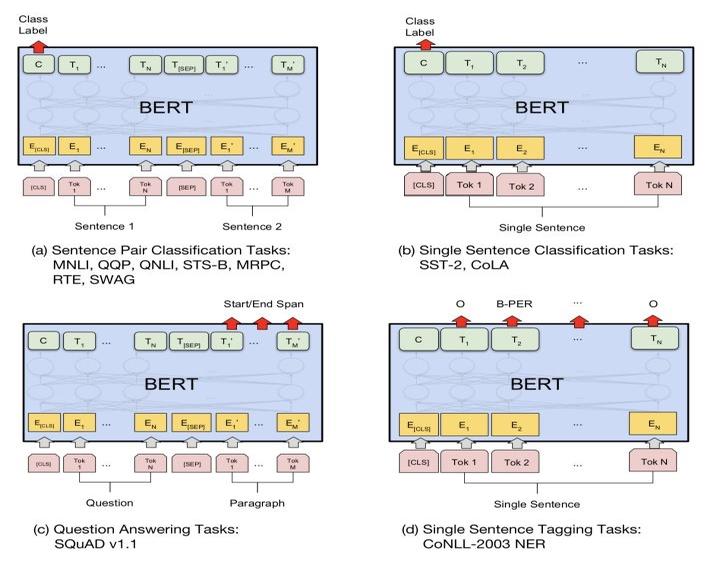
对于sequence-level classification problem(例如情感分析),取第一个token(即[CLS]符号)的输出表示,输入到一个softmax层得到分类结果输出。
对于token-level classification(例如NER),取所有token的最后层transformer输出,输入到softmax层做分类。
实验结果
论文的贡献
(1)证明了双向预训练对语言表示的重要性。与之前使用的单向语言模型进行预训练不同,BERT使用遮蔽语言模型来实现预训练的深度双向表示。
(2)论文表明,预先训练的表示免去了许多工程任务需要针对特定任务修改体系架构的需求。 BERT是第一个基于微调的表示模型,它在大量的句子级和token级任务上实现了最先进的性能,强于许多面向特定任务体系架构的系统。
(3)BERT刷新了11项NLP任务的性能记录。本文还报告了 BERT 的模型简化研究(ablation study),表明模型的双向性是一项重要的新成果。
总结
- 深而窄比浅而宽的模型更好